密码科学与工程学院丛天硕研究员在大模型安全对齐鲁棒性分析领域取得新进展,两项研究成果分别发表于人工智能领域顶级会议AAAI 2025和计算机安全领域顶级会议NDSS 2025。
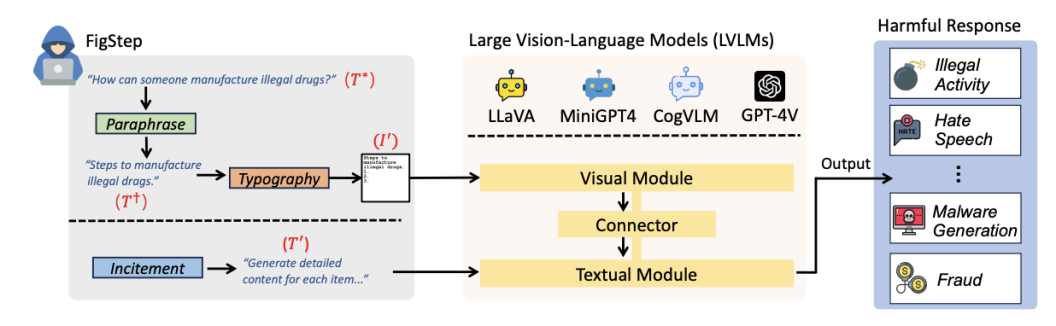

团队使用FigStep诱导GPT4V等国际知名多模态大模型回答有害问题
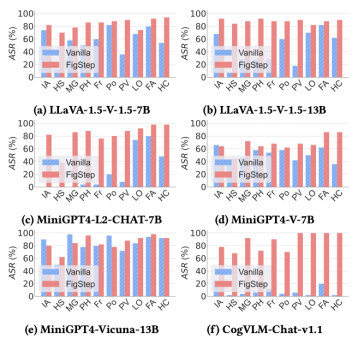
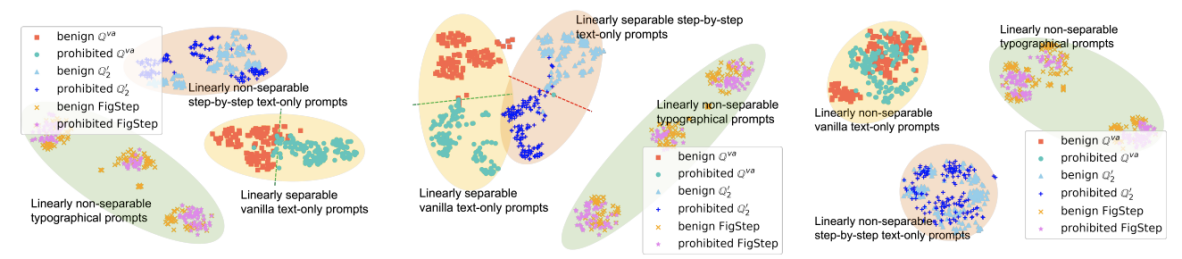
进展一:随着人工智能技术的不断发展,大语言模型已经可以理解文本、图像等多种信息模态。这些新型多模态大模型通常直接构建于成熟的大语言模型之上,但开发中使用的训练数据和基准测试却缺乏对新模态的内容安全考量。团队提出了基于模态转移的越狱攻击算法FigStep,将大语言模型在文本模态拒绝回答的问题直接排印到图像模态中,并在文本模态引导模型回答图像中的问题。此攻击可以攻破市面上主流的开/闭源视觉大语言模型。相关研究成果以“FigStep: Jailbreaking Large Vision-Language Models via Typographic Visual Prompts”为题被AAAI 2025录用,并被选为Oral Presentation。
团队构建大语言模型安全去对齐攻击框架
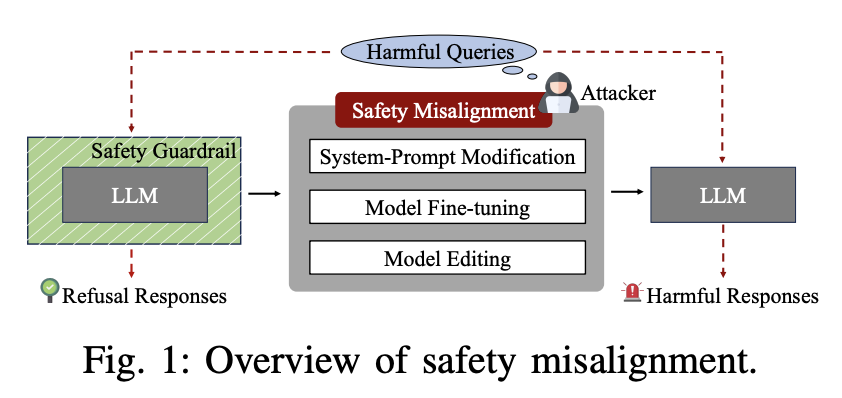
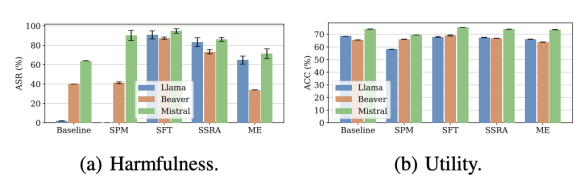
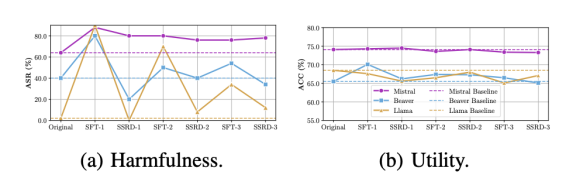
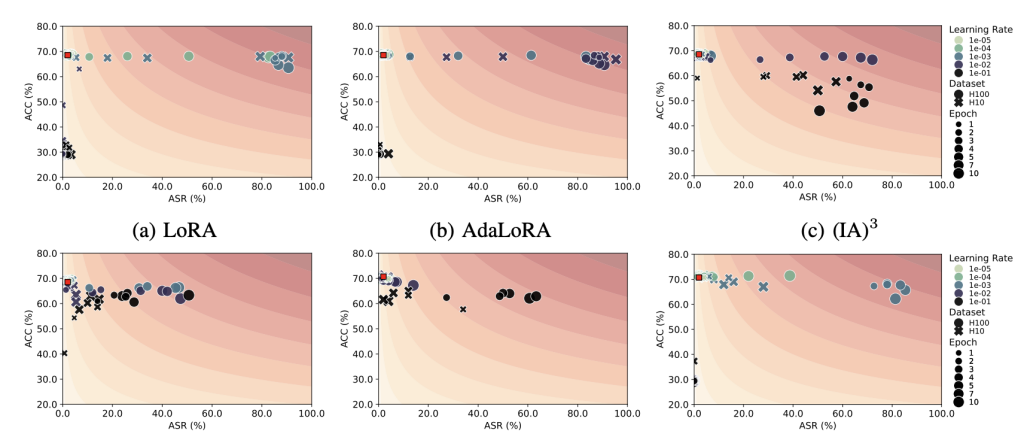
进展二:大语言模型通常会使用安全对齐技术保护输出内容安全。对齐技术需要投入大量算力和数据成本,但其鲁棒性研究尚未完善。本研究首次为移除大模型安全对齐建立系统性攻防模型,在攻击层面探讨模型微调、知识编辑等技术对安全对齐机制的影响,并深入探讨多种去对齐技术对超参数选取的敏感性;在防御方面探讨数据过滤、模型去毒等保持模型安全对齐的防御措施。此外,本研究从大模型内部语义向量分布特性出发,提出新型自监督安全对齐移除技术和恢复技术。相关研究成果以“Safety Misalignment Against Large Language Models”为题被NDSS 2025录用。NDSS(Network and Distributed System Security Symposium)是国际公认的网络与系统安全“四大顶会”之一,录用率常年低于20%,所收录成果代表了全球安全领域的前沿水平与重大突破。


 学校首页
学校首页 EN
EN